DRY & SQL
Often our first step in deriving value from data is to extract and summarize records within our Data Warehouse. Here the lingua franca is SQL. As a declarative language, SQL provides an extremely valuable layer of abstraction allowing us to describe what we want computed without knowing on which exact machine the data is stored nor thinking at all about how to orchestrate this computation. Let’s say we want to compute the number of BTC trades on Coinbase for a given asset month by month:
SELECT
COUNT(*)
, DATE_TRUNC(‘month’, timestamp)
FROM facts.trades
WHERE asset = ‘BTC’
GROUP BY 2
But wait, tomorrow I might need to investigate volume and this time on ETH:
SELECT
SUM(amount) AS volume
, DATE_TRUNC(‘month’, timestamp)
FROM facts.trades
WHERE asset = ‘ETH’
GROUP BY 2
Now we didn’t technically violate DRY, but let’s be honest, we did. The vast majority of the code written to answer these two questions is identical. In particular, we’ve duplicated our knowledge of the storage location and aggregate/filtering fields. And here we get to the core of the problem: Even in a well structured and well documented Data Warehouse, raw SQL queries force us to rewrite the underlying logic of our questions from scratch every time, producing heartbreaking inefficiency, inconsistent answers, and Data Scientists who spend more of their time as Data Librarians.
In this world, our Data Scientists are an embedded part of the machinery that enables us to derive value from our data and without them, we are lost. It looks something like this:
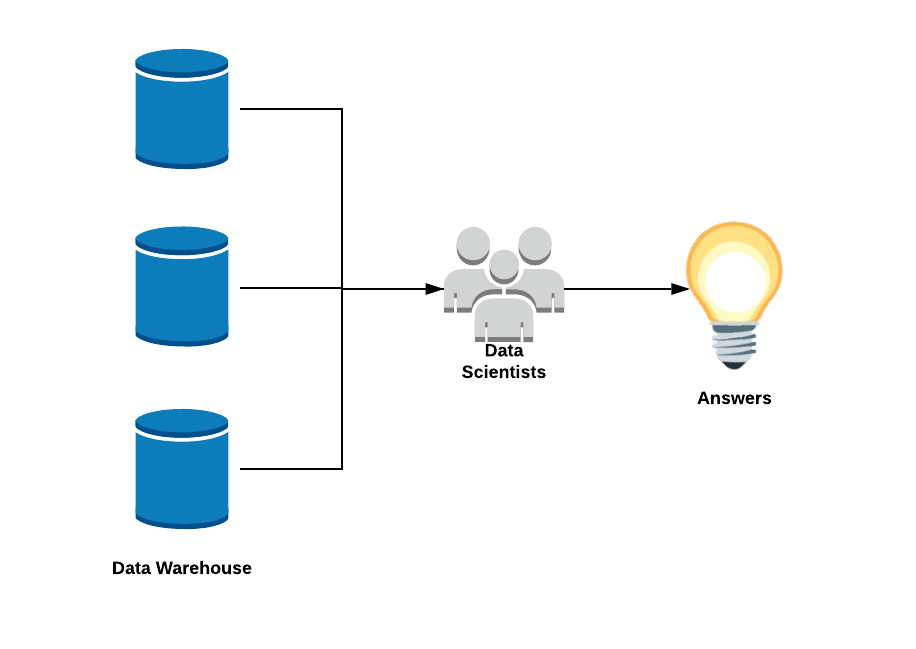
Data Semantics: a level above SQL
Now let’s chart a path out of this inefficiency & endless DRY-violation. At some point we need to write SQL to talk to our Data Warehouse, but this time let’s write it in a way so that it can answer our questions over and over again, even when they change a little bit. If we can manage that we’ll have made a quantum leap forward, making SQL the new bytecode. But we’re getting ahead of ourselves.
To get us started, the concepts we’ll need are:
Measures: aggregatable data records representing the measurement of some quantity, often we’ll sum, average or count the measures contained within individual records to investigate these quantities in aggregate. In the above query we summed up the “amount” measure to get the trading volume
Dimensions: non-aggregatable data records that we may want to use to filter or partition our analysis, giving our analysis the appropriate context. In the above query we filtered by the dimension “asset”
By adding this semantic metadata (measures & dimensions) to the underlying data powering our queries, we can codify which questions this data can answer and enable these questions to automatically be compiled into SQL (again, SQL as bytecode). Here’s an example of how that might look in YAML format.
compute: sqlstorage: facts.trades
measures:
— name: trade_volume
kind: sum
— name: trades
kind: count
dimensions:
— name: asset
kind: string
— name: timestamp
kind: time
Now instead of writing the full query I have a new input
measures: trades
dimensions: month
filters: [asset=BTC]
or
measures: trade_volume
dimensions: month
filters: [asset=ETH]
Admittedly, this looks a lot like a bastardized SQL dialect, and that’s not wrong. But we’ve abstracted away the important parts, namely the aggregation logic (count & sum for trades & volume, respectively) and the storage (facts.trades) so that I’m truly just expressing my core question in a structured way. At Coinbase, we’ve built a centralized API that understands these configurations and orchestrates any requested computation. This has paid huge dividends including:
Separation of Storage: while we’ve focused on SQL, it really doesn’t matter where this data is stored, so long as the records constitute the promised measures and dimensions
Separation of Compute: SQL can easily do counts, sums, etc. But SQL has no monopoly on these computations and other engines can be used as needed.
Single Source of Truth: with a centralized orchestrator managing this metadata we have a single source of truth for measure and dimension definitions enabling us to ensure consistent answers to our most important questions.
In this way we’ve changed the model of how we derive value from data, taking Data Scientists out of the machinery and instead enabling them to configure what the data they manage means:
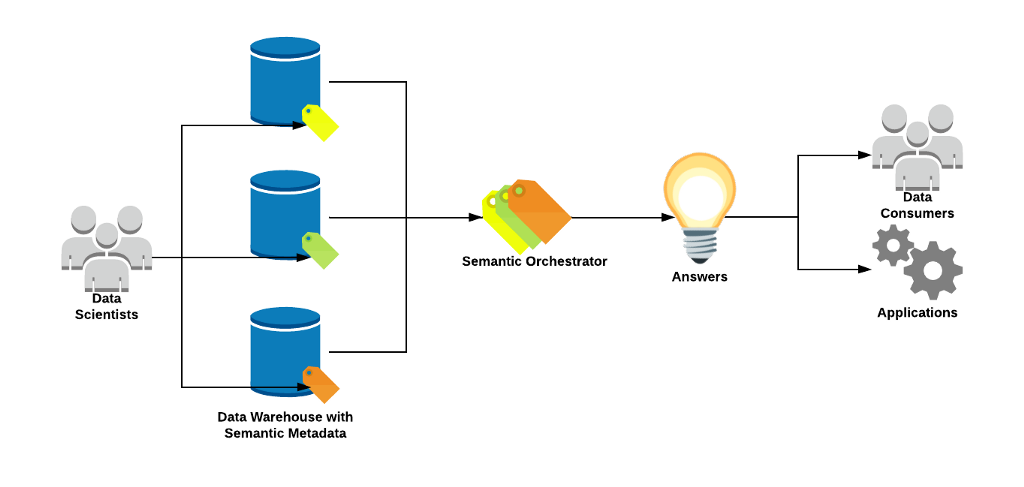
For the sake of brevity, I’m leaving out a ton of the details here but the core concept is what we hope to get across. By codifying the semantic metadata that tells us how to use our various data sources, we can move away from the nuts and bolts process of manually specifying where data lives or how we want it aggregated. Instead, we can start asking our questions at a higher level (e.g. “BTC trades by month”) and let the semantic orchestration layer figure out where such data lives, and which engines should be spun up to aggregate it according to pre-configured methodology.
At Coinbase we have used these concepts to provide a great deal of automation to common Data Science tasks including Executive Reporting, Experimentation, Anomaly Detection, and Root Cause Analysis, all of which build upon the same idea of pre-configuring what the data means and relying on the orchestration layer to interpret this metadata to roll-up any desired quantities. By changing the Data Science workflow from an endless stream of DRY-violations to a coordinated, codified and centralized effort at maintaining a semantic interface, we are moving beyond ad-hoc SQL requests and towards a self-serve, single source of truth view of our business powering an ever expanding set of reliable answers to our most pressing questions.
If you are interested in solving complex technical challenges like this, Coinbase is hiring.
This website contains links to third-party websites or other content for information purposes only (“Third-Party Sites”). The Third-Party Sites are not under the control of Coinbase, Inc., and its affiliates (“Coinbase”), and Coinbase is not responsible for the content of any Third-Party Site, including without limitation any link contained in a Third-Party Site, or any changes or updates to a Third-Party Site. Coinbase is not responsible for webcasting or any other form of transmission received from any Third-Party Site. Coinbase is providing these links to you only as a convenience, and the inclusion of any link does not imply endorsement, approval or recommendation by Coinbase of the site or any association with its operators.
Unless otherwise noted, all images provided herein are by Coinbase.

was originally published in The Coinbase Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.