In 2019, Coinbase set out to strengthen the infrastructure upon which its products are built and to create a solid foundation to support current and future product lines. As part of that effort, we decided to adopt AWS RDS PostgreSQL as our database of choice for relational workloads and AWS DynamoDB as our key-value store.
One of the first areas we decided to focus on was how to keep track of balances and move funds. Our products had each devised their own solutions and some legacy systems were also plagued by tech debt and performance issues. The ability to quickly and accurately process transactions is central to Coinbase’s mission to build an open financial system for the world.
We designed and built a new ledger service to be fast, accurate and serve all current and future needs across products and have undertaken our biggest migration as of yet, moving over 1 billion rows of corporate and customer transaction and balance information from the previous data storage to our new PostgreSQL-based solution, without scheduled maintenance and no perceptible impact to users.
Our key learnings:
Make it repeatable — You may not get it right the first time.
Make it fast — So you can quickly iterate.
Make it uneventful — By designing the process so that it runs without disrupting normal business operations.
Here’s how we did it…
Migration Requirements
Accuracy and Correctness: Since we’re dealing with funds, we knew this would be a very sensitive migration and wanted to take every precaution, make sure that every last satoshi is accounted for.
Repeatable: Additionally, the shape of our data was completely different in the new system vs the legacy system. Further, we had to deal with technical debt and cruft accumulated over time in our monolithic application. We knew we needed to account for the possibility of not getting everything right in a single go, so we wanted to devise a repeatable process that we could iterate on until getting it right.
No Maintenance Downtime: We wanted every transaction on Coinbase to execute while working on this. We didn’t want to do any scheduled maintenance or take any downtime for the transition.
The Setup
We can deconstruct the migration into 2 separate problems: Switching live writes and reads over the new service, and migrating all of the historical data into the new service.
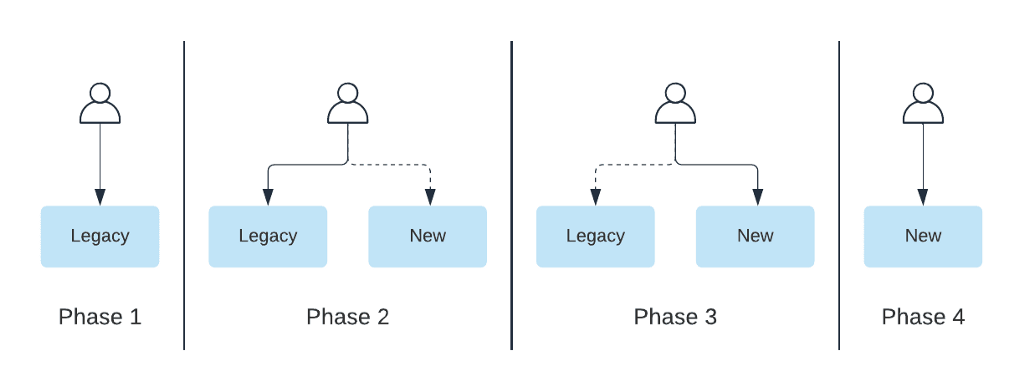
For the migration we decided to take a dual-write / dual-read phased approach. Phase 1 is before the migration, where we only have the legacy system in place. In Phase 2, we introduce the new system. We dual write to both the legacy and new system the read path we read from both, then log discrepancies and return the result from the legacy system. With Phase 3, we’ve built up the confidence in our new setup, so we favor it when returning results. We still have the old system around and can switch back to it if needed. Finally, we phase out unused code to finish the migration (Phase 4).
We won’t go into details about our dual-write implementation, since the general idea has been previously covered by industry blog posts.
What’s interesting is something that happens in between Phase 2 and Phase 3, namely the backfill of all customer data into our new system so that we can achieve parity.
The Repeatable Backfill Process
We considered multiple approaches to backfilling the billion-plus rows that represent all the transactions carried out on Coinbase from its inception, all with pros and cons.
The most straightforward solution would have been to do it all at the application level, leveraging the ledger client implementation we had in place for the dual writes. It has the advantage of exercising the same code paths we have in place for live writes — there would be a single mapping from old to new to maintain. However, we would have had to modify the service interface to allow for the backfill and we would have had to set up long running processes together with a checkpointing mechanism in case of failure. We also benchmarked this solution, and found that it would be too slow to meet our requirements for fast iteration.
We eventually decided to pursue an ETL-based solution. At a high level, this entailed generating the backfill data from the ETL-ed source database, dumping it into S3 and loading it directly into the target Postgres database. One key advantage to this approach is that doing data transformation using SQL is fast and easy. We could run the entire data generation step in ~20 minutes, examine the output, verify internal consistency and do data quality checks directly on the output without having to run the entire backfill pipeline.
Our data platform provider offers a variety of connectors and drivers for programmatic access. This means that we could use our standard software development tools and lifecycle — the code that we wrote for the data transformation was tested, reviewed and checked into a repository.
It also has first-class support for unloading data into S3, which made it easy for us to export the data after provisioning the appropriate resources.
One the other end, AWS provides the aws_s3 postgres extension, which allows bulk importing data into a database from an S3 bucket. Directly importing into live, production tables however proved problematic, since inserting hundreds of millions of rows into indexed tables is slow, and it also affected the latency of live writes.
We solved this problem by creating unindexed copies of the live tables, as follows:
DROP TABLE IF EXISTS table1_backfill cascade;
CREATE TABLE table1_backfill (LIKE table1 INCLUDING DEFAULTS INCLUDING STORAGE);
The import now becomes limited by the I/O, which becomes a bottleneck. We ended up slowing it down a bit by splitting the data into multiple files and adding short sleep intervals in between the sequential imports.
Next up, recreating the indexes on the tables. Luckily, Postgres allows for index creation without write-locking the table, by using the CONCURRENT keyword. This allows the table to continue taking writes while the index is being created.
So far, so good. The real complexity however comes from our requirement to have a migration that doesn’t involve scheduled maintenance or halting transaction processing. We want the target database to be able to sustain live writes without missing a single one, and we want the backfilled data to seamlessly connect to the live data. This is further complicated by the fact that every transaction stores information about the cumulative balances of all accounts involved — this makes it easy for us to evaluate and maintain data integrity and to look up point in time balances for any account at any timestamp.
We solved for this by using triggers that replicate inserts, updates, deletes to the live tables into the backfill tables. Our concurrent index generation allows us to write to these tables while the indexes are being created.
After indexing is complete, in a single transaction, we flipped the backfill and live tables, drop the triggers, and drop the now unneeded tables. Live writes continue as if nothing happened.
At the end of this process, we run another script that goes through all of the data and restores data integrity by recreating the cumulative balances and the links between sequential transactions.
Last but not least, we run another round of integrity checks and comparisons against the legacy datastore to make sure that the data is correct and complete.
Putting it all together, the sequence looks as follows:
Clean slate: reset ledger database, start dual writing
Wait for dual written data to be loaded into ETL, so that we have overlap between live written data and backfill data.
Generate backfill data, unload it into S3
Create backfill tables, set up triggers to replicate data into backfill tables.
Import data from S3
Create indexes
Flip tables, drop triggers, drop old tables.
Run repair script
Verify data integrity, correctness, completeness
The process would take 4 to 6 hours to run and was mostly automated. We did this over and over while working through data quality issues and fixing bugs.
The Aftermath
Our final migration and backfill was not a memorable one. We didn’t have a “war room”, no standby on-call engineers, just another run of our process after which we decided that it was time to flip the switch. Most people within the company were blissfully unaware. An uneventful day.
We’ve been live with the ledger service for almost a year now. We have the capacity to sustain orders of magnitude more transactions per second than with our previous system, and with tight bounds on latency. Existing and new features, such as the Coinbase Card, all rely on the ledger service for fast and accurate balances and transactions.
If you’re interested in distributed systems and building reliable shared services to power all of Coinbase, the Platform team is hiring !
This website contains links to third-party websites or other content for information purposes only (“Third-Party Sites”). The Third-Party Sites are not under the control of Coinbase, Inc., and its affiliates (“Coinbase”), and Coinbase is not responsible for the content of any Third-Party Site, including without limitation any link contained in a Third-Party Site, or any changes or updates to a Third-Party Site. Coinbase is not responsible for webcasting or any other form of transmission received from any Third-Party Site. Coinbase is providing these links to you only as a convenience, and the inclusion of any link does not imply endorsement, approval or recommendation by Coinbase of the site or any association with its operators.
All images provided herein are by Coinbase.

was originally published in The Coinbase Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.